CPU-Optimized Embedding Models with fastRAG and Haystack
Discover how to use optimized embedding models on CPUs to reduce latency, and improve throughput of retrieval and indexing
August 1, 2024One of the main and critical components of a retrieval augmented generation (RAG) pipeline is the embedding process, which forms the foundation for efficient information retrieval by transforming raw text into machine-readable vector representations. Embedding models encode textual data into dense vectors, capturing semantic and contextual meaning. These models are used to create embeddings for both queries (for retrieval) and documents (for indexing and reranking). Therefore, optimizing these models through quantization could improve our RAG application by providing:
- Higher throughput: useful for reducing the time needed for creating or updating your vectors store.
- Lower latency: improves real-time experience as creating query embeddings and re-ranking of documents are done online per user input.
- Reduced memory and cost requirements: Optimizing by quantization to
int8reduces the memory footprint and the cost when running such models.
This is where specialized frameworks, such as fastRAG by Intel Labs, come into play, offering enhancements tailored to specific hardware and use cases, and with the extensive feature-set offered by Haystack.
fastRAG: Intel Labs’ Framework for Efficient RAG
fastRAG is a research framework developed by Intel Labs for efficient and optimized RAG pipelines. It incorporates state-of-the-art large language models (LLMs) and information retrieval capabilities. fastRAG is fully compatible with Haystack and includes novel and efficient RAG modules designed for efficient deployment on Intel hardware, including client and server CPUs (Xeon) and the Intel Gaudi AI accelerator.
The fastRAG GitHub repository provides extensive documentation on each component available in the framework, comprehensive examples, and easy installation instructions for optimized backends. The framework utilizes optimized extensions to popular deep learning frameworks such as PyTorch.
One such extension is Optimum Intel, an open-source library that extends the Hugging Face Transformers library and takes advantage of Intel® Advanced Vector Extensions 512 (Intel® AVX-512), Vector Neural Network Instructions (VNNI), and Intel® Advanced Matrix Extensions (Intel® AMX) on Intel CPUs to accelerate models. AMX accelerated inference is introduced in PyTorch 2.0 and the Intel Extension for PyTorch (IPEX).
Intel and deepset are key members in Open Platform for Enterprise AI (OPEA), a project recently announced by LF AI & Data Foundation. OPEA aims to accelerate secure, cost-effective generative AI (GenAI) deployments for businesses by driving interoperability across a diverse and heterogeneous ecosystem, starting with RAG.
Optimization Process: Quantization
The optimization process involves quantizing the model using a calibration dataset, and leveraging an optimized backend like IPEX for Intel Xeon CPUs. Quantization reduces the model size by converting weights and activations from floating-point (e.g., 32-bit) to lower-bit representations (e.g., 8-bit integers). This makes models smaller, faster, and more cost-efficient, with negligible loss in accuracy. Benchmark results of
BGE-large demonstrate a potential 10x speed-up in the indexing process when using the int8 variant of the model.
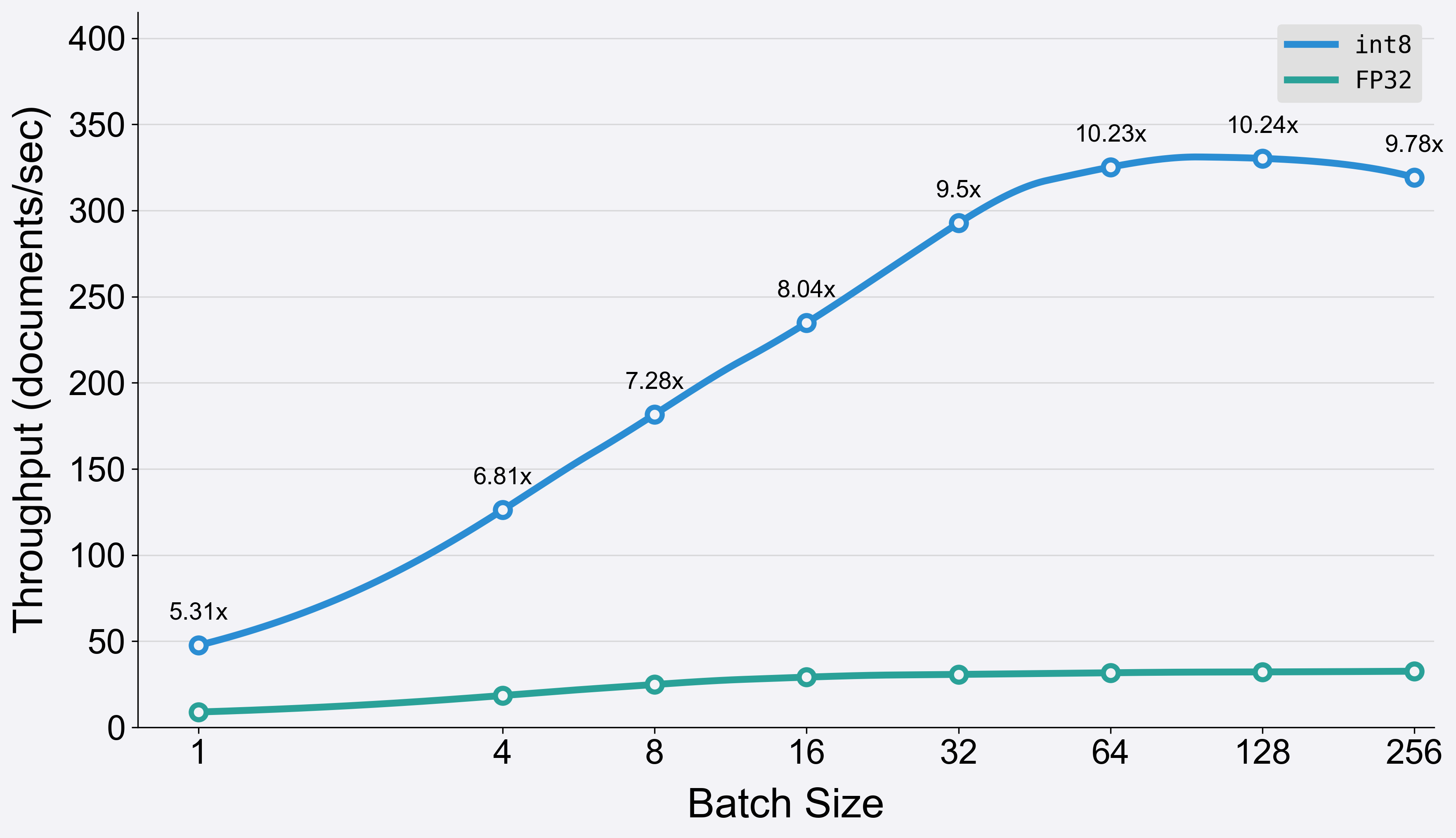
Note that the benchmark results focus solely on the time spent in the encoding process of the BGE-large model variants. Time taken for tokenization is excluded from these measurements to provide a clearer comparison of the models’ encoding efficiency.
A comprehensive guide to quantizing a model from scratch is available. Additionally, three quantized BGE embedding models are available on Intel’s Hugging Face Model Hub.
Components
fastRAG is supported as an integration to Haystack, extending Haystack’s document and text embedders with IPEX support. In addition, fastRAG includes two Bi-encoder similarity rankers:
-
IPEXSentenceTransformersDocumentEmbedder and
IPEXSentenceTransformersTextEmbedder - Embedder components that use an
int8quantized embedding models via IPEX, and can embedDocumentand text inputs. - BiEncoderSimilarityRanker - A bi-encoder similarity ranker that re-orders a list of documents given a query and an embedder. Bi-encoder models are used to encode documents and queries independently and are more efficient than cross-encoders.
-
IPEXBiEncoderSimilarityRanker - An IPEX-based
BiEncoderSimilarityRanker to be used with an
int8quantized embedding model.
See the full list of fastRAG components here.
Same Accuracy, 9x Faster
Maintaining competitive retrieval accuracy is important when optimizing the models. We evaluated the impact of optimization (quantization and calibration) on performance using the Rerank and Retrieval sub-tasks of MTEB with three BGE bi-encoder embedding models. For the BGE-large model, the optimization process marginally altered performance compared to the original model, as shown in the table.
| int8 | FP32 | %diff | |
|---|---|---|---|
| Reranking | 0.5997 | 0.6003 | -0.108% |
| Retrieval | 0.5346 | 0.5429 | -1.53% |
Results for other BGE models can be found here.
Let’s compare encoding random texts as passages using two different models:
-
BAAI/bge-large-en-v1.5 (
fp32) with Haystack’sSentenceTransformersDocumentEmbedder -
Intel/bge-large-en-v1.5-rag-int8-static (
int8) with fastRAG’sIPEXSentenceTransformersDocumentEmbedder
The script below creates random passages, each passage translates into 256 tokens once encoded with the tokenizer, and encodes 16384 passages using the same model in both fp32 and int8 variants.
import time
from datasets import load_dataset
from haystack import Document
from fastrag.embedders import IPEXSentenceTransformersDocumentEmbedder
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Intel/bge-large-en-v1.5-rag-int8-static")
def generate_text_for_fixed_length(seq_length):
text = ""
while True:
# Tokenize the current text
token_ids = tokenizer(text)["input_ids"]
# Check if the tokenized sequence has reached the desired length
if len(token_ids) == seq_length:
break
elif len(token_ids) > seq_length:
text = text[:-1]
# Add a random character to the text
text += random.choice(string.ascii_letters + string.digits + string.punctuation + " ")
return text
seq_length = 256
generated_texts = []
for _ in tqdm(range(1000), desc="Generating texts"):
generated_texts.append(generate_text_for_fixed_length(seq_length))
generated_texts = generated_texts * 20
docs = [Document(content=doc) for doc in generated_texts]
BATCH_SIZE_LIST = [1, 4, 8, 16, 32, 64, 128, 256]
for BATCH_SIZE in BATCH_SIZE_LIST:
print("Running with BATCH_SIZE:", BATCH_SIZE)
ipex_doc_embedder = IPEXSentenceTransformersDocumentEmbedder(
model="Intel/bge-large-en-v1.5-rag-int8-static",
batch_size=BATCH_SIZE
)
haystack_doc_embedder = SentenceTransformersDocumentEmbedder(
model="BAAI/bge-large-en-v1.5",
batch_size=BATCH_SIZE
)
ipex_doc_embedder.warm_up()
haystack_doc_embedder.warm_up()
# Measure runtime for SentenceTransformersDocumentEmbedder
start_time = time.time()
documents_with_embeddings = haystack_doc_embedder.run(docs[:16384])
end_time = time.time()
haystack_doc_embedder_runtime = end_time - start_time
# Measure runtime for IPEXSentenceTransformersDocumentEmbedder
start_time = time.time()
documents_with_embeddings = ipex_doc_embedder.run(docs[:16384])
end_time = time.time()
ipex_doc_embedder_runtime = end_time - start_time
print("Runtime for SentenceTransformersDocumentEmbedder:", haystack_doc_embedder_runtime)
print("Runtime for IPEXSentenceTransformersDocumentEmbedder:", ipex_doc_embedder_runtime)
The runtime results indicate that using the setup of fastRAG’s components, as demonstrated in the script above, leads to 5.25x to 9.3x speed-ups in the embedding process when running on a single socket of a Gen 4 Xeon CPU (8480+) and using 56 cores. We can also translate that to throughput (higher is better) and see the differences in speed-ups as well.
💡 The difference in speedups compared to the benchmark presented previously is due to the extra processing done in Haystack components, mainly, the tokenization process which was excluded in the previous benchmark.
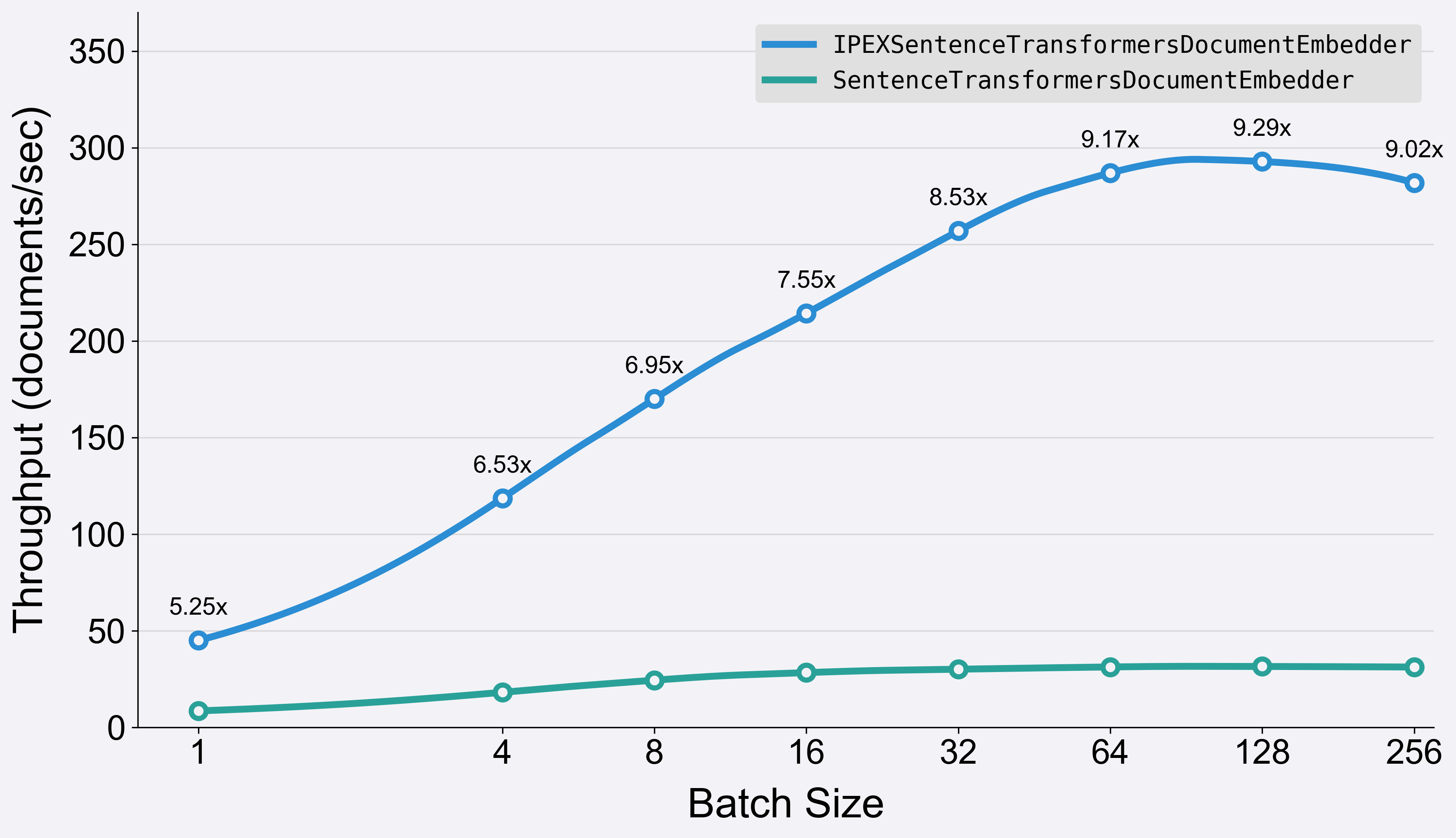
IPEXSentenceTransformersDocumentEmbedder and SentenceTransformersDocumentEmbedder
💡 The performance of the quantized
int8model highly depends on the structure of the data. For best performance, it is advised to use static shapes, meaning, and tokenized sequences of the same length. In addition, batching is highly effective when using CPU backends and it could also be combined with dynamic shapes. It’s a matter of tuning the setup according to the data and hardware.
💡 We followed the instructions available here when running the experiments, which includes using
numactlto limit running the processes on a single socket, and TCMalloc. We recommend reading the performance tuning guide and launch script usage available on the IPEX documentation website.
Read the Intel fastRAG team’s blog with additional evaluations and performance benchmarking for more information.
RAG with Optimized Embedding Models
In this section, we will explore how to use optimized models within a RAG pipeline. We will use embedder models to create the initial index more quickly than the standard fp32 Hugging Face models. Additionally, we will demonstrate a simple Q&A pipeline that employs an optimized bi-encoder ranker. This ranker re-orders the retrieved documents to enhance the list of documents used in the LLM prompt, thereby improving the overall performance of the retrieval process.
Installation
First, install fastRAG, Optimum Intel and Haystack via fastRAG:
pip install fastrag[intel]
Indexing Data
We will start with initializing an in-memory data store and loading the document embedder component from fastRAG. The IPEXSentenceTransformersDocumentEmbedder can be seamlessly integrated into a Haystack pipeline, just like any other component.
from haystack import Document
from haystack.document_stores.in_memory import InMemoryDocumentStore
from fastrag.embedders import IPEXSentenceTransformersDocumentEmbedder, IPEXSentenceTransformersTextEmbedder
document_store = InMemoryDocumentStore()
doc_embedder = IPEXSentenceTransformersDocumentEmbedder(model="Intel/bge-small-en-v1.5-rag-int8-static")
doc_embedder.warm_up()
Now, let’s load a dataset. We’ll use bilgeyucel/seven-wonders dataset that doesn’t need any further processing:
from datasets import load_dataset
from haystack import Document
dataset = load_dataset("bilgeyucel/seven-wonders", split="train")
docs = [Document(content=doc["content"], meta=doc["meta"]) for doc in dataset]
Next, we embed the documents and write them to the index:
documents_with_embeddings = doc_embedder.run(docs)
document_store.write_documents(documents_with_embeddings["documents"])
RAG Pipeline
We continue to initialize components required to build a pipeline that represents a simple Q&A RAG example using an embedder, a retriever, a reranker, a prompt template, and a generator. Notably, the IPEXSentenceTransformersTextEmbedder and IPEXBiEncoderSimilarityRanker can be seamlessly integrated into a Haystack pipeline alongside other components.
Learn how to create a RAG pipeline with Haystack in 📚 Tutorial: Creating Your First QA Pipeline with Retrieval-Augmentation.
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
from fastrag.rankers import IPEXBiEncoderSimilarityRanker
query_embedder = IPEXSentenceTransformersTextEmbedder(model="Intel/bge-small-en-v1.5-rag-int8-static")
retriever = InMemoryEmbeddingRetriever(document_store, top_k=100)
reranker = IPEXBiEncoderSimilarityRanker("Intel/bge-large-en-v1.5-rag-int8-static", top_k=5)
We create a simple RAG prompt template:
from haystack.components.builders import PromptBuilder
template = """
You are a helpful AI assistant. You are given contexts and a question.
You must answer the question using the information given in the context.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{question}}
Answer:
"""
prompt_builder = PromptBuilder(template=template)
We initialize a
HuggingFaceLocalGenerator with
HuggingFaceTB/SmolLM-1.7B-Instruct model (SmolLM-1.7B-Instruct using a local Hugging Face model) to generate answers:
from haystack.components.generators import HuggingFaceLocalGenerator
generator = HuggingFaceLocalGenerator(model="HuggingFaceTB/SmolLM-1.7B-Instruct",
task="text-generation",
generation_kwargs={
"max_new_tokens": 100,
"do_sample": False,
})
Finally, we create the pipeline:
from haystack import Pipeline
pipe = Pipeline()
pipe.add_component("retriever", retriever)
pipe.add_component("embedder", query_embedder)
pipe.add_component("reranker", reranker)
pipe.add_component("prompt_builder", prompt_builder)
pipe.add_component("llm", generator)
pipe.connect("embedder", "retriever")
pipe.connect("retriever", "reranker.documents")
pipe.connect("reranker", "prompt_builder.documents")
pipe.connect("prompt_builder", "llm")
Try the Pipeline
Let’s try the pipeline with a real question:
question = 'What does Rhodes Statue look like?'
response = pipe.run({'embedder': {'text': question},
'reranker': {'query': question},
'prompt_builder': {'question': question}})
print(response['llm']['replies'][0])
>>> The statue was a Colossus of Rhodes, a statue of the Greek sun god Helios that stood in the city of Rhodes and was one of the Seven Wonders of the Ancient World. It is said to have stood about 100 feet (30 meters) tall, making it the tallest statue of its time. The statue was built by Chares of Lindos between 280 and 240 BC. It was destroyed by an earthquake in 226
Summary
In this short blog, we’ve highlighted the significant advantages of CPU-optimized embedding models in terms of accuracy and performance, demonstrating how seamlessly these components can be incorporated into your Haystack pipeline. At the forefront of these advancements is fastRAG, a research library dedicated to integrating Intel-based optimizations into Haystack.
The fastRAG team provides in-depth information on the quantization process and extensive benchmarking conducted on 4th Gen Xeon processors. To dive deep into the optimizations, read this detailed blog post and join our Discord community to explore Haystack.

